Latest Product Updates
Videos
Watch the latest videos on the Livepeer Youtube ChannelForum
Contribute to trending Forum Discussions
Embody SPE: Pre-proposal Intelligent Public Pipelines
Hello everyone. The Embody SPE presents it’s proposal for intelligent public good pipelines. It is not a final version and improvements are ongoing, so feel free to leave any feedback with a forum post.
Embody SPE: Intelligent Public Pipelines
Authors: DeFine(de_fi_ne) (strategy & engineering), Dane(dane3d) (virtual worlds & avatars)
note: discord handles are enclosed in brackets after author names.
Abstract
Embody is an open-source network for embodied agents, powered by Livepeer orchestrator compute and designed to interact directly with the hardware layer of the network. This proposal outlines a paradigm shift from manually managed pipelines to a network of automanaged public pipelines. In this model, the embodied agents are the pipelines—intelligent, semi-autonomous entities that reside within the orchestrator’s Docker containers. The agents intelligently decide when to spawn avatars and initiate workloads based on network demand, hardware capabilities, and direct negotiation with consumers.
The Embody SPE is the team behind the development and maintenance of these open-source pipelines. The team members also operate a for-profit company (Atumera LLC, a Delaware company) which actively uses(https://embody.zone) and maintains the pipeline infrastructure. This ensures the open-source pipelines have a committed, long-term commercial user from day one, driving real-world usage and providing a continuous feedback loop for improvement.
**Prior Work:**You can find our most current retrospective here https://forum.livepeer.org/t/embody-team-retrospective/3215
The Problem: Pipelines are passive.
Livepeer’s GPU network is built for scale, but its value is constrained by the nature of its workload demand. Most current usage is episodic, and more importantly, the pipelines themselves are passive. They are predefined workflows that cannot adapt, learn, or optimize themselves. This creates a continuous error of omission; orchestrators cannot optimally match their unique hardware capabilities to the best possible workloads, missing opportunities for value creation.
The Solution: Automanaged intelligent Public Pipelines.
We propose to solve this by injecting intelligence into the pipeline itself. Instead of orchestrators managing static pipelines, the pipelines will be fully automated via agents—handling their own engineering, maintenance, optimization, consumer outreach, and workload allocation. This creates a dynamic, self-managing, and intelligent network.
System Architecture
We offer two views of the system architecture: a high-level interaction flow and a detailed layered view of the agent itself.
System Interaction Flow
This diagram shows the end-to-end flow of a consumer request through the Embody network, including the agent’s ability to leverage co-residual workflows and deliver content directly to any destination.
Layered Agent Architecture
This diagram breaks down the internal structure of the Embodied Agent, from the network interface down to the hardware.
The Economic Model: Roles & Incentives
This new paradigm introduces clear roles and incentives, governed by a smart contract layer:
-
What Consumers Get: Consumers can purchase three primary services: (a) Embodied Agent time for specific interactive tasks, (b) access to the output of network-only information, drawing from the swarm’s collective intelligence without accessing the raw data itself, and (c) agent-optimized workloads, which are capabilities the agents either create specifically for the host hardware or optimize from existing services.
-
Orchestrator Participation: Orchestrators are incentivized to participate in two ways:
- Become a Workload Provider: An orchestrator can choose to become a Workload Provider, taking on the liability for the agent’s actions but also capturing the full value it creates. For our initial testing phase, Embody will cover the operational costs for participating orchestrators.
- Cognitive Contribution: Even without being a Workload Provider, an orchestrator can earn incentives by interacting with and steering the agent. 50% of the Incentives budget’s weekly staking rewards are allocated here. Contribution is measured by on-chain actions that verifiably improve the network, such as providing high-quality feedback on agent performance, flagging suboptimal workload generation, or submitting hardware-specific optimization profiles.
Swarm Intelligence and Self-Improvement
The Embody network is a decentralized swarm where agents, built on the OpenClaw framework, can interact and share information, creating a powerful network effect. Crucially, these agents can self-improve at the agent layer—modifying their own skills and configurations. With each update to the underlying LLMs, the entire network of agents grows more intelligent, creating a virtuous cycle of continuous improvement.
Financial Management & Transparency
All funds will be managed by a 2-of-3 multisig wallet that requires a co-signer from the Livepeer Foundation for all transactions, ensuring accountability and alignment with the network’s best interests. We are committed to full transparency, with all expenses tracked via public, receipt-based spend reports.
Budget Allocation & Accrual Packages
The $65,000 budget is allocated into four distinct accrual packages, each with its own defined behavior, designed to maximize transparency and long-term value.
1. Team Spending Package
-
Amount: $32,000
-
Asset: Held as staked LPT.
-
Behavior: This package is designed for direct team compensation. The base allocation is paid out in LPT bi-weekly over the 4-month period. All staking rewards accrued within this package are also paid out bi-weekly, split equally between the two developers.
2. Incentives Package
-
Amount: $20,000
-
Asset: Held as staked LPT.
-
Behavior: This package funds network growth, and its principal is never depleted. At the end of each week, the staking rewards generated by this package are split: 50% is spent on orchestrator and network incentives, and the other 50% is compounded back into the principal, continuously growing the incentives pool for long-term sustainability.
3. Operational Costs Package
-
Amount: $8,000
-
Asset: Liquidated to USDC upon receipt.
-
Behavior: This package provides a stable buffer for predictable operational expenses, including cloud infrastructure, agent API costs, and software expenses. Holding these funds in USDC removes volatility risk for essential services.
4. Security Package
-
Amount: $5,000
-
Asset: Held as staked LPT.
-
Behavior: This package is dedicated to network security. The principal is held as staked LPT, allowing it to mature and grow in value. The staking rewards accrued can be used to fund a bug bounty program and other AI safety incentives, allowing us to proactively address security without touching the core audit funds until they are needed.
Overflow Mechanism
To ensure operational continuity, an overflow mechanism is in place. During the initial grant inflow event only, if the LPT received for the Operational Costs package converts to less than $8,000 USD worth of stablecoin due to market volatility, the deficit will be drawn equally from the Team Spending and Incentives packages and liquidated to USDC. This one-time mechanism ensures the operational budget is fully funded from day one. It does not imply that we will maintain infrastructure after the initial $8,000 is depleted.
Safety, Liability, and Governance
Our approach is built on rigorous testing, layered security, and clear liability.
-
Liability Framework: Liability is tied directly to authorization. The entity that authorizes an agent’s action—whether a corporate entity like Atumera LLC, an orchestrator acting as a Workload Provider, or an end-user via a
skill.mdfile—has the liability. -
Phased Rollout & Testing: The pipeline will be launched in a closed alpha with a limited set of trusted orchestrators to thoroughly test all safety and economic models before a public release.
-
Safety Mechanisms: The system includes an always-on moderation layer for safety policy violations and a mandatory killswitch for orchestrators and operators to terminate any workload they deem unsafe.
Risk Mitigation
-
Risk: Smart contract vulnerability.
-
Mitigation: Our budget includes a dedicated fund for a professional third-party security audit, and we will run a bug bounty program funded by the Security bucket’s staking rewards.
note: This list is actively updated.
Scope (4 Months)
| Month | Primary Outcomes |
|---|---|
| 1 | Start of controlled centralized phase; release of agent pipeline in closed alpha; develop v1 of the smart contract layer; establish on-chain KPI publishing pipeline with TEE attestations. |
| 2 | Conduct security audits and hardening; focus on workload aggregation. No major releases during this phase. |
| 3 | Implement feedback from Month 2; introduce automated information aggregation and feedback improvement loops into the system. Public orchestrator release. |
| 4 | Decentralized stage, full Handover of pipeline management + incentives bucket to the community as public good - Release of decentralized public pipeline. Thank you for taking the time to read this proposal, and to those who participate in the Embody pipelines already, thank you for your enduring support. We are continuously working to improve our operations and offered services, if you think we can make something better, please let us know by leaving a comment |
Pre-proposal: Put the brakes on LPT emissions
This is a discussion thread for a candidate parameter change LIP related to token emissions in the Livepeer Network. It is the output of work originally announced in Continuing discussions on Inflation and discussed there, on Discord, and in the water cooler chat.
It’s time to bring the discussion down to earth with a concrete proposal. Please read it here: [PROPOSAL]
For additional context, consult @dob’s discussion thread on LIP-100 from last March.
I will maintain an FAQ section in this post as discussion evolves.
FAQ
How will this affect Orchestrators and Delegators?
The upper tail of possible yield outcomes for H1 2026 comes down, reducing uncertainty. Yearly trailing yield remains above 60% with high confidence. See the relevant section of the proposal.
If we vote to pass this proposal, what happens after that? What do we do past the end of the forecast period?
The simplest thing we can do is consult the community again for updated objective-setting, rerun the simulations, and if deemed necessary, propose another parameter LIP with updated parameters. There is also more that could be done to streamline this process and make it more robust. See the relevant section of the proposal.
Why do we want to do this?
There is a lot to say on this topic and as many of you reading this know, it has been discussed extensively. Our view is explained in detail — including exposition of how the emissions system works now, what it is for, how it has been performing, and why we might want to bring it under control — in the relevant section of the proposal.
How did you use the responses to the November survey?
The November survey revealed clear themes within community opinion, including what we saw as broad agreement that Livepeer would be better off if emissions slowed down. However, it also revealed a diversity in understanding of what the emissions system actually does, how it impacts different actors within the system, and the plausible rationales for bringing down emissions.
Respondents were asked to give quantitative targets for yield and dilution, and we received a very broad range of responses — too broad, in my opinion, to use any of those numbers as objectives on the basis of community agreement. I’m aware that people were confused by some of these questions, and want to reassure you that we did not take your responses as a mandate to treat those particular numbers as objectives.
The only specific number from the survey data that we used directly was the bonding rate threshold of 40%, a figure that was found acceptable to nearly all the respondents to one of the most straightforward questions on the survey. This was used in our modelling as an acceptance threshold for simulation outcomes — we wouldn’t accept any parameter settings that allowed bonding rate to drop this low (and we didn’t find any such settings, anyway).
How are emissions are on track to be higher than last year if participation is already over 50%?
We’re not claiming emissions are “probably” going to be higher than last year, just that there is a significant risk that they will be. Participation is over 50% now, but it can go up or down in the future. By looking at the size of historic stake movements, we can estimate the size of this risk.
What are the current parameters set to again? How much of a change is this?
The current value of targetBondingRate is equivalent to 50%. Our proposal is to reduce it by four percentage points. This is a much smaller reduction than has been considered in earlier models.
The current value of inflationChange is 500. We are proposing to increase that to 700. That has the effect of compressing timelines on emission rate changes by 40%. For example, if emissions carry on trending down, under the new parameter setting it will come down in ten days as much as it would otherwise have done in 2 weeks.
The outcome of these changes is so small, why are we bothering? Shouldn’t we be trying to drastically reduce emissions?
The space of parameter tunings for this mechanism is still mostly unexplored. Making a moderate adjustment keeps us close to familiar territory while still giving us high confidence that things are moving in the right direction.
Moreover, even under much more aggressive tweaks to inflationChange, the emission rate would take a while to come down to the point that we’d see major changes to aggregate quantities like 1Y trailing yields. So regardless of what we do, the community has some time to observe how the effect of the changes play out and, if necessary, recalibrate mid-year.
The current system is working as intended.
Not a question, but a sentiment we’ve seen enough times to warrant a response.
Every mechanism deserves to have its objectives (what it’s intended to do) and performance (whether it actually does it) reviewed to see if they still serve the community’s objectives. That’s what we’ve done with our community survey, proposal, and risk report.
- We asked the community what they think about the 50% target, and almost no one considered it a red line: anything over 40% bonding rate is perfectly fine. So if the price adjustment mechanism’s job is to keep the bonding rate over (or at) some threshold, there is no reason to insist that threshold be 50%.
- We studied the performance of the adjustment mechanism from a theoretical and empirical perspective, and found little evidence to support the claim that very high emissions are necessary or sufficient for high participation. If they aren’t, it’s really unclear how they can be worth the risk of externalities, which have been discussed at length elsewhere.
Will this make the token price go up?
While of course every proposal ought to serve the long range goal of increasing the value of the network, we don’t claim this is going to have any immediate impact on token price. Our proposal is about preserving the capital pool and limiting wastage, not pumping the token.
We should implement an emissions cap.
Another common suggestion. Our proposal is a soft touch approach to the same goal as an emissions cap: prevent emissions from growing uncontrollably. Implementing this proposal does not rule out introducing an emissions cap later on.
Shouldn’t we wait until fees are enough to sustain Os before cutting emissions?
Orchestrators need emissions-funded rewards to support their operations until fees are enough to make an unsubsidised O sustainable. That subsidy isn’t going away. We’re talking about walking emissions back towards levels they were a year ago, when fee income was even less than it is now: this isn’t unexplored territory for Os. We don’t have to wait until fees ramp up.
Why should I, a staker, vote to prioritise non-stakers?
Catering to non-stakers is not the priority. It’s a question of balance: managing emissions-based rewards is about managing a tradeoff between diluting non-stakers and incentivising staking. Our proposal is to fine-tune this balance, because the incentive to stake is already enough to sustain adequate levels of staking — not to prioritise non-stakers above stakers.
Acknowledgements
I’m grateful to @b3nnn for feedback and suggestions on the framing of this proposal. I would also like to thank @Jonas_Pixelfield and Arunas from Pixelfield for their valuable input in the early stages of the project. This work was commissioned by the Livepeer Foundation.
Discord
Add your voice to the latest Discord DiscussionsThe proposal funds Cloud SPE to build a focused MVP for standardized, publicly observable network performance, reliability, and demand metrics, making the network measurable and comparable while laying the groundwork for future SLA-aware routing and scaling.
Vote Yes ✅ or No ❌ here ↗
All network value depends on protocol security. The proposal argues for a dedicated, continuously staffed function for protocol security, upgrades, and core improvements, replacing the current ad hoc model with a single accountable structure.
Vote Yes ✅ or No ❌ here ↗
X Posts
Follow, Like, Comment & Share on the latest Livepeer X postsBlogs
Read recent news from the Livepeer Blog
The AI x Open Media Forum, hosted by the Livepeer Foundation and Refraction during Devconnect Buenos Aires, brought together artists, technologists, curators, protocol designers, founders and researchers at a moment when media is being reshaped at its foundations. Real-time AI has moved from experimental edges into active use, influencing how creative work is made, how it circulates, how it is authenticated and how value flows through entire ecosystems.
The Forum was designed as a symposium rather than a conventional conference. Instead of panels, participants sat together in tightly focused groups, comparing lived experience with emerging technical capabilities and identifying where the next wave of open media infrastructure must come from. The premise was simple:
If AI is rewriting the conditions of cultural production, the people building the tools and the people using them need to be in the same room.
Across the day, it became clear that AI has begun to reconfigure creative labour. Participants described shifts in authorship, changes in access to tools and compute and growing pressure to navigate accelerated production cycles. The discussions documented in this report trace how these changes are being felt on the ground and outline the early primitives that may support an open, verifiable and creatively expansive media ecosystem.
I. Methodology and framing questions for the forum
The Forum opened with a set of framing questions that clarified the core pressures at the intersection of AI and culture. They were selected because they touch the foundations of creative practice, technical design and the incentives that organise contemporary media systems. These questions served as a shared structure for the day, guiding both creative and technical groups toward the points where their worlds intersect most directly.
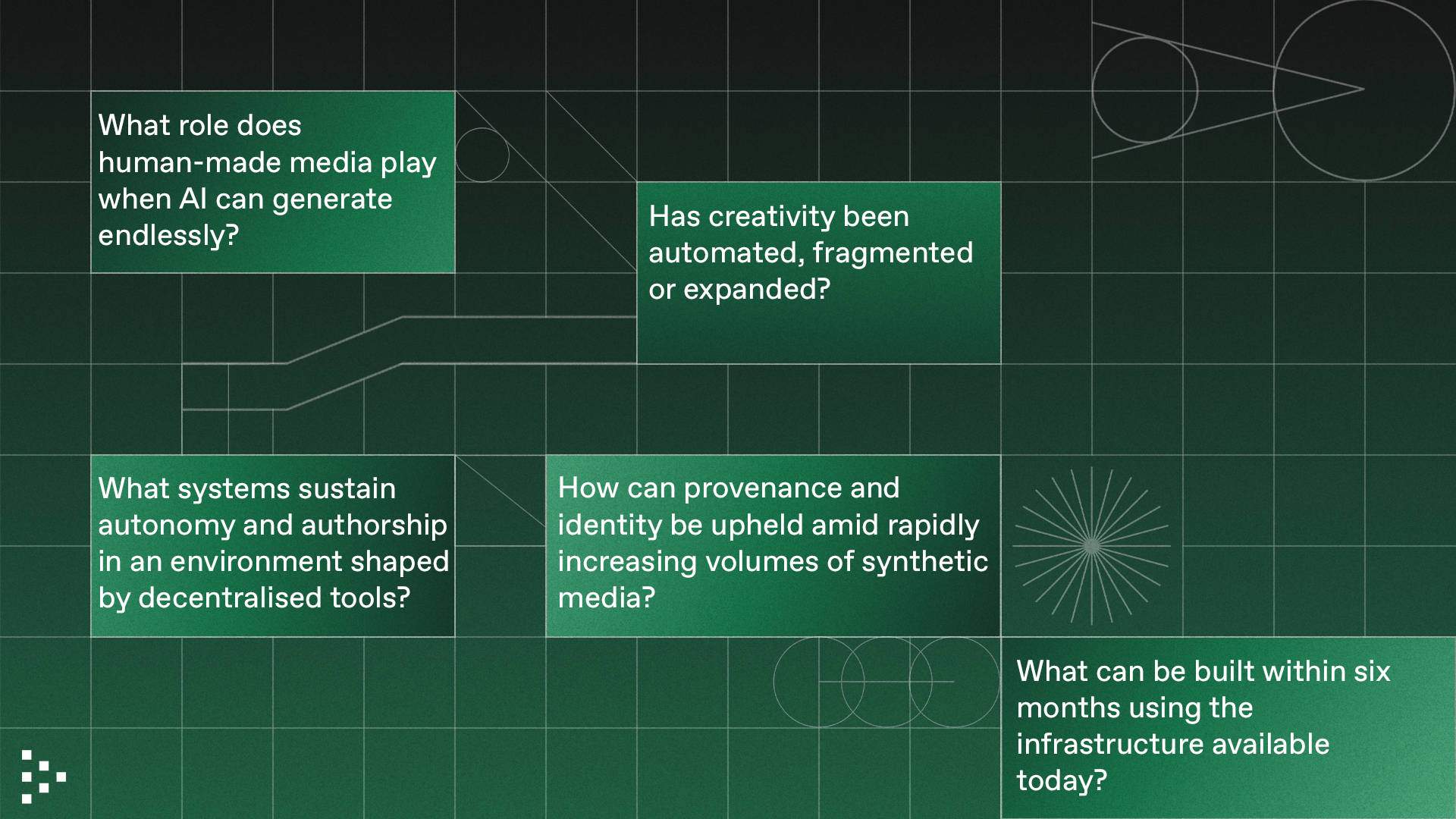
These questions created a common orientation for participants with very different backgrounds. Artists used them to describe how these pressures appear in their work. Technologists used them to identify where current systems break and where new primitives might be possible. The result was a focused dialogue in which creative insight and technical reasoning informed one another. As the day progressed, these initial questions became more specific, grounded in concrete examples and shaped by the experiences of the people who are building and creating with AI right now.
II. Creative track: New wave creativity in the age of AI
The creative discussions opened a clear window into how AI is reshaping cultural practice. Artists, designers and musicians described shifts they are already living through: changes in authorship, new pressures around speed, and the expanding role of computation in what can be made and shared. Their experiences formed the human foundation for understanding the technical challenges that surfaced later in the day.
1. The persistence of authorship and the idea of “code”
One of the most important contributions came a Venezuelan 3D artist artist who articulated how personal history and cultural memory form a kind of creative signature. They described this as their “code”: a composite of experience, environment and emotional texture that cannot be reduced to visual style alone.

“My code is my personal language, shaped by the places I come from,” they explained. “I photograph the decadence of Venezuela and turn it into something romantic. AI can remix it, but it cannot replace where I’m from.”
This idea resonated widely across the room. Participants recognised that while AI can convincingly emulate aesthetics, it cannot reconstruct lived experience. The concern is not simply stylistic mimicry; it is the potential erosion of the cultural grounding that gives creative work its meaning.
Serpentine Gallery curator Alice Scope added context from contemporary art: “Some artists will use these tools to push aesthetic extremes. Others will return to minimalism. That tension has always driven art history.” The consensus was that AI is entering a lineage of tools that have historically reshaped creative practice, but its scale introduces new stakes around identity and authorship.
2. Compute access as a determinant of creative possibility
A structural insight emerged as creators discussed their workflows: access to compute is not evenly distributed. Several participants from Latin America and other regions described how GPU scarcity and cost have become the limiting factor in pursuing their practice.
One participant underscored the issue: “I couldn’t do what I do without Daydream. GPUs are too expensive here. This is the only way I can work at the level I want.”
This was not framed as a complaint but as a recognition that compute access is now a primary determinant of who can participate in emerging creative forms. It became clear that compute, not talent or tools, is increasingly the gatekeeper of participation. This topic resurfaced repeatedly across both tracks and became one of the keystones of the entire Forum.
3. Discovery systems and the changing behaviour of audiences
Creators then turned to the challenge of reaching audiences. Traditional distribution remains shaped by opaque algorithms and engagement-driven incentives, often misaligned with the values and intentions of artists.
Almond Hernandez from Base described the dilemma: “If you remove algorithms entirely, you place the burden of discovery back on users. But if you keep them, they can distort culture. We need ways for people to shape their own feeds.”
This tension produced no single consensus, but it clarified a shared frustration: discovery should not force creators into optimising for platform dynamics. Instead, systems must emerge where identity, provenance and community input meaningfully influence what is surfaced.
Friends With Benefits CEO Greg Breznitz articulated the broader implication: “Culture and technology cannot be separated anymore. What gets rewarded changes the art that gets made.” The group recognised that discovery systems are not neutral and actively shape the evolution of cultural forms.
4. How AI is reshaping the creative process from the inside

Perhaps the most nuanced discussion centred on how AI alters creative labour. Participants avoided easy dichotomies of “AI as threat” versus “AI as tool.” Instead, they articulated a more layered understanding: AI accelerates exploration but also compresses the time available for deeper creative development.
Franco noted that the pressure to produce quickly “can corrupt the process,” a sentiment echoed by musicians and digital artists who described being pulled toward workflows optimised for speed, not refinement.
A music platform founder contextualised this through the lens of distribution: “Platforms can train bots to listen to the AI music they create, just to farm plays.” This raised concerns about synthetic ecosystems that siphon attention away from human artists.
Yet the group also acknowledged that AI unlocks new capacities. It lowers technical barriers, enabling more people to express ideas without specialised training. For many, it expands the field of imagination.
Malcolm Levy of Refraction offered a framing rooted in art history: “Every movement in art is shaped by the tools of its time. Digital art was marginal until suddenly it wasn’t. AI will be the same. What matters is who shapes it.”
Across this discussion, an essential truth emerged: AI does not eliminate creativity. It redistributes the labour involved, elevates the importance of intention and shifts the points at which authorship is asserted.
III. Technical track: Shaping the infrastructure for trust, agency and scale

While the Creative Track articulated what must be protected and what must remain possible, the Technical Track explored how to design systems that support those needs.
1. Provenance as foundational infrastructure
The technical discussion on provenance opened with a recognition that no single method can guarantee trust in an AI-saturated media environment. Participants approached provenance as an infrastructure layer that must operate across the entire lifecycle of media creation. They examined device-level capture signals, cryptographic attestations, model watermarking, social proof, dataset lineage and content signatures, emphasising that each approach addresses a different vector of uncertainty.
The importance of this layered approach became clear through the most grounded example offered during the session. A team building a voice-data contribution platform described their experience collecting human audio samples. Even after implementing voice-signature checks and running deepfake detectors, they found that “about ten percent of the data was actually faked.” Contributors were training small voice models on their own samples and then using those models to fake additional submissions. “Validation needs human listeners, model detection and economic incentives working together,” they explained. It illustrated a key point: provenance is a dynamic adversarial problem and must be treated as such.
This example shifted the discussion from idealised architectures to applied constraints. Participants concluded that provenance must be multi-layered, adversarially robust and economically grounded. A validator network that incorporates human judgment, machine detection and stake-based incentives was seen as a promising direction, not because it solves provenance outright but because it distributes trust across diverse mechanisms rather than centralising it in a single authority or detector. In a digital landscape stricken with antiquated copyright frameworks that hinder both the creation, dissemination and remuneration of artistic works, a multi-nodal, human-centric approach to provenance feels refreshing, urgent and necessary.
The discussion also connected provenance to discovery and reputation. If identity and content lineage can be verified at creation time, those signals can later inform how media is surfaced, filtered or contextualised. Provenance, in this framing, is not only about defending against deepfakes but about enabling a more trustworthy environment for cultural production, circulation and monetisation.
2. Infrastructure for global creativity: compute, identity and discovery as interdependent primitives
Over the course of the day, participants identified a pattern: compute, provenance and discovery are not separate concerns. They form an interdependent system that determines:

Compute inequality emerged again as a core issue. Without access to real-time inference, creators are excluded from participating in emerging media forms. Provenance systems ensure that outputs can be trusted, and discovery mechanisms determine whether meaningful work reaches an audience.
This preceded a rich conversation about discovery architecture. What if users could port their data across platforms to surface relevant content, instead of the platforms selling this data back to users?
Participants explored how portable identity, content signatures, verifiable histories and community-shaped surfacing could form a new discovery layer that operates independently of platform-level ranking algorithms. In this model, discovery becomes a protocol rather than a product: a configurable, interoperable layer where authorship, reputation and provenance act as first-class signals.
Building open media requires a tightly interwoven stack. Compute enables creation; provenance secures identity and authorship; discovery amplifies credible work in ways that reflect the values of specific communities rather than a single optimisation function.
Treating these components as independent problems would reproduce the failures of existing platforms. Treating them as interdependent primitives opens the possibility for a healthier and more diverse media ecosystem.
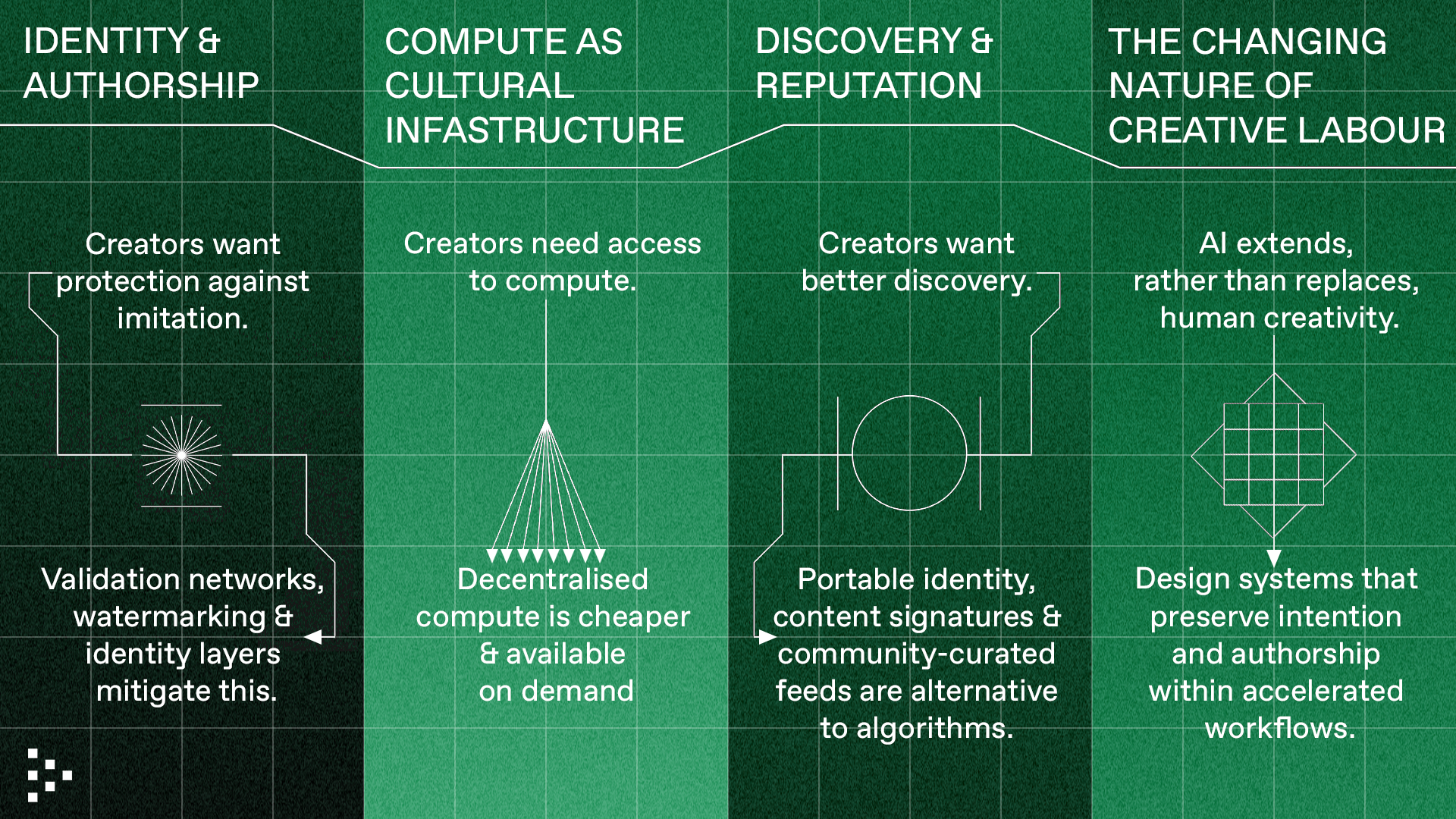
IV. Synthesis
When the creative and Technical tracks were read side by side, several coherent themes emerged.
VI. Conclusion
The Forum made clear that the future of media will depend on coordination between creative and technical communities.
Artists articulated what must be preserved: identity, context, agency and the integrity of the creative process. Technologists outlined the systems that can support those needs at scale.
This event functioned as a working laboratory. The insights surfaced here will inform follow-up research, prototypes and collaborative development. Livepeer and Refraction will continue publishing materials from the Forum and supporting teams exploring these early ideas.
Open media will not emerge from a single protocol or organisation, but from a community building the foundation together.


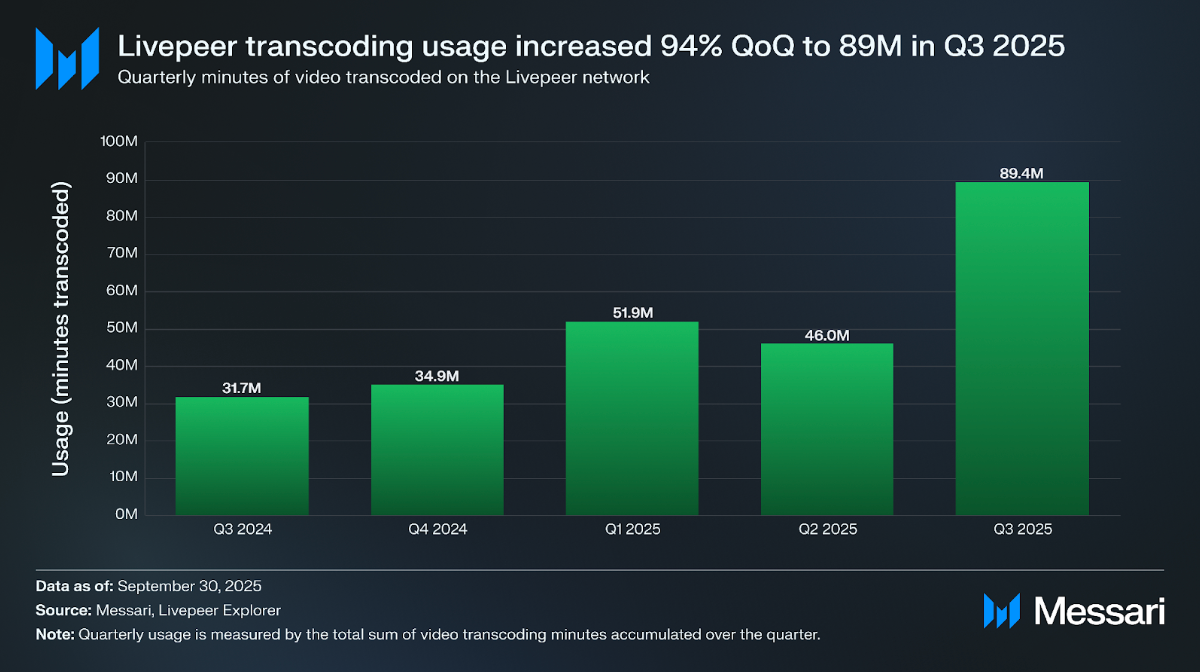
For the past year, the Livepeer Ecosystem has been guided by the Cascade vision: a path to transition from a pure streaming and transcoding infrastructure, to an infrastructure that could succeed at providing compute for the future of real-time AI video. The latest Livepeer quarterly report from Messari highlights that this transition is paying off, with network fees up 3x from this time last year, and over 72% of the fees now driven via AI inference. This is exemplified by the growing inspirational examples emerging from Daydream powered real-time AI, and real-time Agent avatar generation through Embody and the Agent SPE.
This shift has been an ecosystem wide effort – ranging from branding and communications, to productization and go to market, to hardware upgrades for orchestrators. It has successfully shifted the project under an updated mission and direction, however it has still left ambiguity in terms of what the Livepeer network itself offers as killer value propositions to new builders outside of the existing ecosystem. Is it a GPU cloud? A transcoding infra? An API engine? Now that there are signs of validation and accelerated momentum around an exciting opportunity, it’s time to really hone in on a refined vision for the future of the Livepeer network as a product itself.
The market for video is set to massively expand
The concept of live video itself is expanding well beyond a simple single stream of video captured from a camera. Now entire worlds and scenes are generated or enhanced in real-time via AI assistance, leading to more immersive and interactive experiences than possible via old-school streaming alone. For a taste of the future, see the following examples:
- The future of gaming will be AI generated video and worlds in real-time:
AI games are going to be amazing
— Matt Shumer (@mattshumer_) October 23, 2025
(sound on) pic.twitter.com/66aOdWJr4Y
- Video streams can be analyzed and data leveraged programmatically in real-time, for instant insight generation and decision making:
3 years since I joined roboflow
— SkalskiP (@skalskip92) October 29, 2025
- 68k stars on github
- 60 videos and streams on youtube
- 2.5M views in total
- 40 technical blogposts
↓ coolest stuff I made pic.twitter.com/EMy5qWq1Vp
- Real-time style transfer can enable avatars and agents to participate in the global economy:
🇨🇳 We’re screwed … it becomes indistinguishable from reality
— Lord Bebo (@MyLordBebo) October 30, 2025
Ali’s Wan 2.2 lets you stream without showing your face. It maps your voice and motion onto another face. pic.twitter.com/iD4nQIVaRY
Video world models and real-time AI video are merging, as they both use AI to generate frame-by-frame video output with low latency on the fly, based on user input and AI inference. This requires a tremendous amount of GPU compute, and requires an amazing low latency video streaming and compute stack – two areas in which the Livepeer network and community thrive, and two areas to which the many other generic GPU inference providers in the market bring no unique skillset, experience, or software advantage.
The big opportunity for the Livepeer network is to be the leading AI Infrastructure For Real-Time Video.
From interactive live streaming to generative world models, Livepeer’s open-access, low-latency network of GPUs will be the best compute solution for cutting edge AI video workflows.
World models are a game changing category, and Livepeer is well suited to offer a unique and differentiated product here, that serves a huge market of diverse and varying use cases. These range from creative entertainment, to gaming, to robotics, to data analysis, to monitoring and security, to synthetic data generation for AGI itself.

While an ambitious stretch, Nvidia executives responsible for the category have even projected that due to the impact in robotics, the economic opportunity for world models could exceed $100 trillion, or approximately the size of the entire global economic output itself!
What does it mean to productize the Livepeer network to succeed as a valuable infrastructure in this category?
From a simplified viewpoint, it needs to deliver on the following:
1. Ability for users to deploy real-time AI workflows to the Livepeer network and request inference on them
2. Industry leading latency for providing inference on real-time AI and world model workflows.
3. Cost effective scalability – users can pay as they go to scale up and down capacity and the network automagically delivers the scale required.
Imagine a gaming platform is powering world-model generated games using their unique workflows that generate game levels or areas in a certain style by combining several real-time models, LLMs, and style transfer mechanisms. Each game its powering has users exploring and creating their own corners of the interactive worlds, based on prompts and gameplay inputs. Every gamer that joins a game represents a new stream of AI video compute, and the Livepeer network is the backing infrastructure that provides the compute for this video world generation, leveraging hundreds or thousands of GPUs concurrently.
For this to be possible the Livepeer network needs to enable that game platform to deploy their game generation workflow. It needs to offer low latency on the inference that runs this workflow, relative to the generic GPU compute clouds. The pricing needs to be competitive vs alternative options in the market for this GPU compute. And the network needs to allow this company to scale up and down the number of GPUs that are currently live ready to accept new real-time inference streams based on the number of users currently live on the games it is powering.
All of this is possible on the Livepeer network, and it isn’t far away from where we are now. If we work to build, test, and iterate on the Livepeer network itself towards supporting the latency and scale required for these types of workflows, we’ll be set up to power them.
Now multiply this example gaming company by the high number of diverse industries and verticals that real-time AI and world models will touch. Each category can have one or multiple companies competing to leverage this scalable and cost effective infrastructure for unique go to markets targeting different segments. And they can all be powered by the Livepeer network’s unique value propositions.
Livepeer’s core network is strategically positioned
What are these value propositions that make the Livepeer network differentiated relative to alternative options in the market? I’d argue that there are three primary, table stakes, must-have value propositions if Livepeer is to succeed.
1. Industry standard low latency infrastructure specializing in real-time AI and world model workflows: First of all, the network needs to let its users deploy custom workflows. Inference alone on base models is not enough and does not represent scaled demand. Users want to take base models, chain them together with other models and pre/post processors, and create unique and specialized capabilities. When one of these capabilities is defined as a workflow, that is the unit that needs to be deployed as a job on the Livepeer network, and the network needs to be able to run inference on it. Secondly, for these real-time interactive use cases, latency matters a lot. Generic GPU clouds don’t offer the specialized low latency video stacks to ingest, process, and serve video with optimal latency, but Livepeer does. And Livepeer needs to benchmark itself to have lower or equal latency to alternative GPU clouds for these particular real-time and world model use cases.
2. Cost effective scalability: GPU provisioning, reservations, and competing for scarce supply procurement creates major challenges for AI companies – often overpaying for GPUs that sit idle most of the time in order to guarantee the capacity that they need. The Livepeer network’s value proposition is that users should be able to “automagically” scale up almost instantly and pay on demand for the compute that they use, rather than having to pre-pay for reservations and let capacity sit idle. This is enabled by Livepeer taking advantage of otherwise existing idle longtail compute through its open marketplace, and its supply side incentives. The Livepeer network needs to be more cost effective than alternative GPU clouds within this category - with impacts comparable to the 10x+ cost reduction already demonstrated in live video transcoding delivered by the network.
3. Community driven, open source, open access: The Livepeer project and software stack is open source. Users can control, update, and contribute to the software they are using. They also can be owners in the infrastructure itself through the Livepeer Token, and can benefit from the network’s improvements and adoption, creating a network effect. The community that cares about its success and pushes it forward collectively, can be a superpower, relative to the uncertain and shaky relationship between builders and centralized platform providers, who have a history of getting rugged based on limitations to access, changes in functionality, or discontinuity of the platforms. Anyone can build on the Livepeer network regardless of location, jurisdiction, use case, or central party control.
The above are primary value propositions that should appeal to nearly all users. And we must work to close the gaps to live up to those value props before we could successfully hope to go to market and attract new vertical-specific companies to build directly on top of the network. Luckily, in addition to all of Livepeer’s streaming users, we have a great realtime AI design partner in Daydream, which is already going to market around creative real-time AI, using the network, and contributing to its development to live up to these requirements. While building with this design partner, the ecosystem should be working to productize to live up to these promises in a more generic perspective – it should be setting up benchmarks, testing frameworks, and building mechanisms for scaling up supply ahead of demand, so that it can represent this power to the world alongside successful Daydream case studies.
Opportunities to push towards this vision
To truly live up to these value propositions, there are a number of opportunities for the community to focus on in order to close some key gaps. There are many details to come in more technical posts laying out roadmaps and execution frameworks, but at a high level, consider a series of milestones that take the network as a product from technically functional, to production usable, to extensible, to infinitely scalable:
- Network MVP - Measure what matters: Establish key network performance SLAs, measure latency and performance benchmarks, and enhance the low latency client to support realtime AI workflows above industry grade standards.
- Network as a Product - Self adaptability and scalability: Network delivers against these SLAs and core value props for supported realtime AI workflows. Selection algorithms, failovers and redundancy, and competitive market price discovery established for realtime AI.
- Extensibility - Toolkit for community to deploy workflows and provision resources: Workflow deployment and signaling, LPT incentive updates to ensure compute supply for popular AI workflows exceeds demand.
- Parallel Scalability: Manage clusters of resources on the network for parallel workflow execution, truly unlocking job types beyond single-GPU inference.
Many teams within the ecosystem, from the Foundation, to Livepeer Inc, to various SPEs have already started operationalizing around how they’ll be contributing to milestones 1 and 2 to upgrade the network to deliver against these key realtime AI value propositions.
Conclusion and Livepeer’s opportunity
The market for the opportunity to be the GPU infrastructure that powers real-time AI and world models is absolutely massive – the compute requirements are tremendous - 1000x that of AI text or images - and real-time interaction with media represents a new platform that will affect all of the above-mentioned industries. The Livepeer network can be the infrastructure that powers it. How we plan to close the needed gaps and achieve this will be the subject of an upcoming post. But when we do prove these value propositions, Livepeer will have a clear path to 100x the demand on the network.
The likely target market users for the network are those startups that are building out vertical specific businesses on top of real-time AI and world model workflows. The ecosystem should look to enable one (or multiple!) startups in each category going after building real-time AI platforms that serve gaming, that serve robotics, that serve synthetic data generation, that serve monitoring and analysis, and all the additional relevant categories. The network’s value propositions will hopefully speak for themselves, but in the early stages of this journey, it is likely the ecosystem will want to use incentives (like investment or credits) to bootstrap these businesses into existence. Each will represent a chance at success, and will bring more demand and proof.
Ultimately, many users of these platforms may choose to build direct on the network themselves. Similarly to how startups start to build on platforms like Heroku, Netlify, or Vercel, and then as they scale and need more control and cost savings they build direct on AWS, and then ultimately move to their own datacenters after reaching even more scale – users of Daydream or a real-time Agent platform built on Livepeer, may ultimately choose to run their own gateways to recognize the cost savings and control and full feature set that comes from doing so. This is a good thing! As it represents even more usage and scale for the network, more proof that as an infrastructure the Livepeer network has product market fit, and that it can absorb all workflows directly. The businesses built on top will provide their own vertical specific bundles of features and services that onboard that vertical specific capacity, but they’ll be complemented by and enabled by the Livepeer Network’s superpowers.
While there’s a lot of work ahead, the Livepeer community has already stepped up to cover tremendous ground on this mission. At the moment by already powering millions of minutes of real-time AI inference per week, by our orchestrators already upgrading their capacity and procurement mechanisms to provide real-time AI-capable compute, and by the Foundation groups already working to evaluate the networks incentives and cryptoeconomics to sustainably fund and reward those contributing to this effort, we’re set up well to capture this enormous opportunity!